data Masking چیست و چه تکنیکهایی دارد؟

پنهان کردن دادهها یا همان data masking درواقع فرآیند مخفی سازی دادههای اصلی است و هدف اصلی آن پنهان کردن دادههای حساس مانند دادههای شخصی است که در پایگاه دادهی اصلی ذخیره شده است. نکتهی مهم اما این است که در data masking دادهها همچنان قابل استفاده باقی میمانند.
سؤال از این مطلب
سؤال خود را بپرسید؛ پاسخ فقط بر اساس همین مقاله است.
پنهان کردن دادهها یا همان data masking درواقع فرآیند مخفی سازی دادههای اصلی است و هدف اصلی آن پنهان کردن دادههای حساس مانند دادههای شخصی است که در پایگاه دادهی اصلی ذخیره شده است. نکتهی مهم اما این است که در data masking دادهها همچنان قابل استفاده باقی میمانند. با فیسیت همراه باشید تا به توضیح کامل این مسئله بپردازیم.
Data masking چیست؟
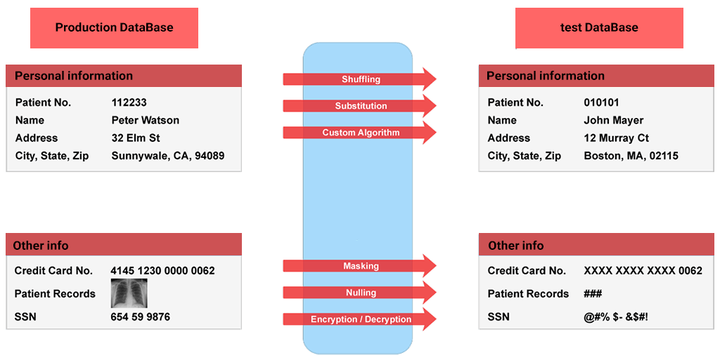
Data Masking به معنای داده پوشی یا مبهم سازی دادههاست. این روش درواقع یک ترفند برای ایجاد نسخهای جعلی از روی دادههای اصلی سازمان است که اگرچه جعلی هستند اما همچنان واقعی به نظر میرسند. از جمله اهداف آن میتوانیم به محافظت از دادههای حساس و ایجاد دادههای کاربردی در شرایطی که به دادههای اصلی نیاز نداریم (مثلا زمانی که دادهها برای آموزش، تست نرم افزار، فروش دمو برنامه و... لازمند)، اشاره کنیم. درواقع فرآیند Data Masking به این گونه است که ضمن حفظ کردن فرمت، مقدار و ارزش دادهها را تغییر میدهد تا این نسخهی ایجاد شده از دادهها، با استفاده از رمزگشایی و یا مهندسی معکوس، قابل تشخیص نباشند. روشهای مختلفی برای تغییر دادهها وجود دارد که در ادامه به توضیح آنها میپردازیم.
چرا و چه زمانی از Data Masking استفاده کنیم؟
یکی از مهمترین دلایلی که باعث میشود سازمانها به سراغ Data Masking بروند، حل بسیاری از مشکلات امنیتی مثل از بین رفتن دادهها، سرقت دادهها (data exfiltration) و... است. از جمله دلایل دیگر استفاده از این روش امنیتی میتوانیم به کاهش خطرات ناشی از استفاده از فضای ابری، غیرقابل استفاده کردن دادهها برای هکرها (این در حالی است که بسیاری از خصوصیات ذاتی دادهها حفظ شده است)، اجازه به اشتراک گذاری دادهها با کاربران احراز هویت شده (مثلا برای تست کنندهها، توسعه دهندگان و...) بدون افشای دادهی اصلی، پاک سازی دادهها (درواقع حتی زمانی که دادهها را حذف میکند، ردی از آنها باقی میماند که خود این مسئله دلیلی برای امکان بازیابی دادههاست. اما پاک سازی دادهها به این معناست که دادههای واقعی با دادههای ماسک شده جایگزین میشوند) اشاره کنیم.
گاهی سازمان نیاز دارد تا به منابع خارجی و سازمانهای third-party فعال در زمینهی IT دسترسی استفاده از پایگاههای دادهاش را بدهد. در این شرایط باید به نحوی امنیت دادهها را تامین کنید که برای این افراد و حتی هکرها، دادهها کاملاً واقعی به نظر برسند و شک برانگیز نباشد.
گاهی هم سازمان نیاز دارد تا خطای اپراتورهایش را کاهش دهد . معمولاً سازمانها برای اتخاذ تصمیمهای درست و مناسب، به کارمندان خود اعتماد میکنند، با این حال بسیاری از نقصهایی که ایجاد میشود، نتیجهی خطای انسانی است. اگر دادهها به روش خاصی ماسک شوند، میتوانند خطاهای فاجعهبار را کاهش دهند.
سازمانهایی که با دادههای حساس مثل اطلاعات شناسایی کاربران (PII)، اطلاعات پزشکی افراد (PHI)، اطلاعات حساب و کارت بانکی افراد (PCI-DSS)، اطلاعات مالکیت معنوی (ITAR) و... کار میکنند، میتوانند از دیتا ماسکینگ بهره ببرند.
انواع Data Masking
دیتاماسکینگ به چندین نوع مختلف برای حفظ امنیت دادهها مورد استفاده قرار میگیرد که عبارتند از Static Data Masking ،Deterministic Data Masking و On-the-Fly Data Masking و Dynamic Data Masking . در ادامه به توضیح هر یک میپردازیم.
Static Data Masking
از طریق این روش میتوانید یک کپی از پایگاه دادهی پاک سازی شده در اختیار داشته باشید. در طی این فرایند عملاً همهی دادههای حساس تغییر داده میشوند تا یک کپی از پایگاه داده ایجاد شود که بتوانیم آن را با امنیت خاطر به اشتراک بگذاریم. معمولاً در این روش ابتدا یک کپی از پایگاه داده به عنوان بکآپ میگیریم، در یک محیط متفاوت آن را لود کرد، تمامی اطلاعات اضافی آن را حذف کرده و سپس دادههای باقی مانده را Mask میکنیم. حالا دادههای ماسک شده را میتوان به نقطهی هدف انتقال داد.
Deterministic Data Masking
در این روش عملاً دو مجموعهی داده از یک نوع و فرمت واحد در اختیار داریم که همواره یکی از این دادهها با دادهی دیگر جایگزین میشود. برای مثال در هر نقطهای از پایگاه داده نام “John Smith” همواره با نام “ Jim Jameson" جایگزین میشود. این روش برای شرایط مختلفی از جمله تست دادهها و... کاربردی است اما ذاتاً امنیت پایینتری دارد.
On-the-Fly Data Masking
این روش درواقع دیتا ماسکینگ در زمانی است که دادهها در حال انتقال از سیستمهای تولیدی به سیستمهای تست یا توسعه هستند و هنوز روی دیسک ذخیره نشدهاند. سازمانهایی که نرم افزارها را به سرعت deploy میکنند، نمیتوانند یک کپی از پایگاه داده منبع به عنوان بک آپ تهیه کرده و Data Masking را روی آن اعمال کنند و نیاز دارند که دائماً دادهها را از تولید به چندین محیط تست استریم کنند. در روش On-the-Fly، هر بار یک جزء از دادههای ماسک شده که به آن نیاز است ارسال میشود. سپس هر بخش از این دادههای ماسک شده، در محیط تست یا توسعه ذخیره میشوند تا توسط سیستم غیرتولیدی مورد استفاده قرار بگیرند.
Dynamic Data Masking
این روش تقریباً مشابه با روش On the fly است با این تفاوت که داده در هیچ نقطهی ثانویهای مثل محیط تست یا توسعه نگهداری نمیشود. به عبارتی دادهها مستقیماً از سیستم تولیدی به صورت استریم برای مصرف سیستم در محیط تست یا توسعه ارسال میشود.
تکنیکهای Data Masking
سازمانها برای ماسک کردن دادههای حساس خود میتوانند از تکنییکهای مختلفی بهره ببرند که در ادامه به تعدادی از معمولترین تکنیکهایی که مورد استفاده قرار میگیرد، اشاره میکنیم.
Data Encryption
زمانی که دادهها با الگوریتمهای رمزنگاری ماسک میشوند، کاربر بدون در اختیار داشتن کلید، عملاً قادر به استفاده از دادهها نیست. این تکنیک امنترین فُرم دیتا ماسکینگ است اما پیاده سازی آن سخت است زیرا به تکنولوژی رمزنگاری دادهها و همچنین مکانیزم به اشتراک گذاری امن کلید نیاز داریم.
Data Scrambling
این تکنیک بسیار ساده است و تنها جای همهی کاراکترهای عبارات را به صورت رندوم تغییر میدهد. برای مثال یک شماره مانند 76498 به شمارهی 84967 تغییر میکند. اگرچه این تکنینک بسیار ساده است اما مشکل اینجاست که روی همهی دادهها امکان استفاده از آن وجود ندارد و البته امنیت آن هم چندان بالا نیست.
Nulling Out
در این روش زمانی که کاربر احراز هویت نشدهای درخواست دادهای را داشته باشد، مقدار Null (دادهای که مقداری ندارد یا گم شده است) برای او به نمایش در میآید. نقطه ضعف این روش در اینجاست که با هدف تست و توسعه، کمتر میتوان از دادهها بهره برد.
Value Variance
در این حالت مقدار دادههای اصلی با استفاده از یک تابع (برای مثال تفاوت بین بیشترین و کمترین مقدار در یک سری) جایگزین میشوند. برای مثال اگر یک مشتری چندین محصول را خریداری کرده است، مقدار هزینهی خرید او را میتوانیم با میانگین بین قیمت گرانترین و ارزانترین کالای خریداری شده توسط او، جایگزین کنیم. این تکنیک ضمن اینکه دادهی اصلی را فاش نمیکند، یک مقدار بسیار کاربردی در اختیار ما قرار میدهد که برای اهداف مختلف میتوانیم از آن استفاده کنیم.
Data Substitution
در این روش مقدار اصلی دادهها با مقادیر جعلی اما صحیح جایگزین میشوند. برای نمونه نام مشتریها را به صورت رندوم با بین تعدادی نام که در یک دفترچه تلفن است، جایگزین میکنیم.
Data Shuffling
این روش شباهت زیادی به Data Substitution دارد با این تفاوت که دادههای یک پایگاه داده، با دادههای همون پایگاه داده جایگزین میشوند. درواقع ترتیب دادهها در هر ستون تغییر میکند. در نهایت خروجی دریافتی از این پایگاه داده کاملاً واقعی به نظر میرسد اما رکوردها در مجموع واقعی نیستند.
بهترین ابزارهای دیتا ماسکینگ
از جمله بهترین ابزارهای Data Masking میتوانیم به موارد زیر اشاره کنیم:
DATPROF – Test Data Simplified
Microsoft SQL Server Data Masking
Oracle Data Masking and Subsetting
IBM InfoSphere Optim Data Privacy
و...
مطلب مرتبط:
معرفی ابزار SQLmap؛ یکی از معروفترین ابزارهای SQL injection
اگر به اخبار دنیای تکنولوژی علاقه مند هستید، ما را در شبکههای اجتماعی مختلف تلگرام، روبیکا، توییتر، اینستاگرام و آپارات همراهی کنید.
منبع: imperva

مطالب مرتبط


1 دیدگاه
سلام بسیار ممنون