

یادگیری ماشین یکی از حوزههای کاربردی در دنیای کنونی است. یکی از سادهترین اما کاربردیترین الگوریتمهای یادگیری ماشین، KNN است که در ادامه به بررسی آن میپردازیم.
الگویتم KNN یکی از سادهترین الگوریتمهای کلاسیفیکیشن است که در یادگیری ماشین کاربردهای زیادی دارد و به شدت استفاده میشود. اما KNN چیست؟ در ادامه با فیسیت همراه باشید تا این الگوریتم کاربردی را به شما معرفی کنیم.
KNN چیست؟
این الگویتم (K نزدیکترین همسایه)، یکی از الگوریتمهای پر استفادهی یادگیری ماشین است که جزء الگوریتمهای بدون پارامتر (یعنی هیچ فرضی در مورد توزیع دادهها ندارد) و lazy leaner (زمان یادگیری کوتاه اما زمان حدس زدن طولانی) است. هدف این الگوریتم استفاده از دیتاستهایی است که نقاط داده در آنها به صورت مجزا بوده و در چندین دسته قرار گرفتهاند.
غیر پارامتری بودن این الگوریتم بسیار خوب است زیرا اغلب دادهها در دنیای واقعی از فرضیات نظری معمول، تبعیت نمیکنند. از این رو زمانی که دانش قبلی درباره توزیع دادهها نداریم، یکی از بهترین گزینهها برای کلاسه بندی، استفاده از الگوریتم KNN است.
روش کارکرد KNN
عملکرد این الگوریتم مبتنی بر شباهت ویژگیهاست. به عبارتی زمانی که یک دادهی تست در اختیار ما قرار میگیرد، با توجه به میزان شباهت آن به دادههای آموزشی، برچسب کلاس آن را مشخص میکنیم.
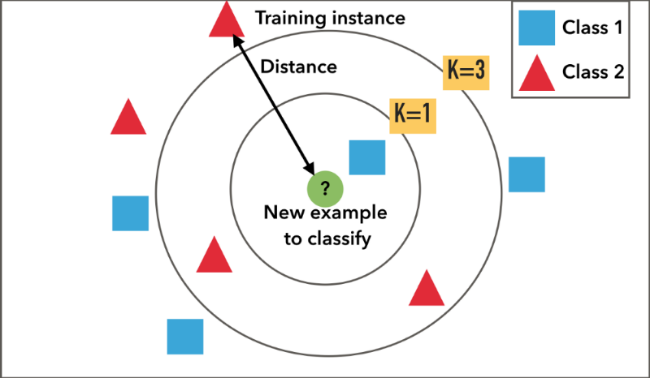
برای مثال به تصویر زیر نگاه کنید. همانطور که میبینید، دو کلاس مثلث قرمز و مربع آبی در اختیار داریم. حالا تصمیم داریم تا برای دادهی تست که با دایرهی سبز نشان داده شده، لیبل مناسب را تشخیص دهیم. همانطور که مشاهده میکنید، لیبل دادهی تست با توجه به تغییر مقدار K تغییر میکند. برای نمونه اگر از 1NN استفاده کنید، یعنی با استفاده از 1 نزدیکترین همسایه، مدل یادگیری را انجام دهد، لیبل دادهی تست مربع آبی خواهد بود. حالا اگر K=3 را انتخاب کنیم و درواقع 3NN را داشته باشیم، لیبل دادهی تست مثلث قرمز خواهد بود زیرا در بین سه دادهای که در نزدیکترین فاصله با دادهی تست قرار گرفتهاند، دو مثلث قرمز و یک مربع آبی به چشم میخورد. بنابراین مثلثهای قرمز که تعداد بیشتری دارند، لیبل کلاس دادهی تست را تعیین میکنند. درواقع از رأی اکثریت (majority vote) برای تعیین لیبل کلاس نمونهی تست استفاده میکنیم.
مزایا و معایب KNN
از جمله مزایای الگوریتم KNN میتوانیم به سادگی این الگوریتم، عدم نیاز به در اختیار داشتن فرضیات دربارهی داده (که مخصوصاً در خصوص دادههای غیرخطی بسیار کاربردی است)، دقت بسیار بالا، کاربردی برای انواع مسائل (کلاسیفیکیشن و رگرسیون) اشاره کنیم.
با این وجود این الگوریتم نقاط ضعفی هم دارد. یکی از مهمترین نقاط ضعف آن، حجم زیاد محاسبات است زیرا این الگوریتم تمامی دادههای آموزشی را نگهداری میکند. همین موضوع باعث میشود تا به حافظهی بسیار زیادی هم نیاز داشته باشیم. از طرفی زمان حدس زدن (prediction) این الگوریتم هم طولانی خواهد بود. از طرفی ویژگیهای غیر مرتبط و اندازهی دادهها هم روی این الگوریتم تأثیر میگذارد.
مطالب مرتبط:
الگوریتم یادگیری ماشین SVM چیست
اگر به اخبار دنیای تکنولوژی علاقه مند هستید، ما را در شبکههای اجتماعی مختلف تلگرام، روبیکا، توییتر، اینستاگرام و آپارات همراهی کنید.
منبع خبر: usejourna

ثبت نظر