

در بخش قبلی کلیاتی دربارهی یادگیری ماشین، انواع و کاربردهای آن توضیح دادیم. در این آموزش اما قصد داریم یکی از الگوریتم مهم و ضروری در این حوزه با نام SVM را به شما معرفی کنیم. با معرفی معروفترین الگوریتمهای یادگیری ماشین، همراه فیسیت باشید.
در بخش قبلی کلیاتی دربارهی یادگیری ماشین، انواع و کاربردهای آن توضیح دادیم. در این آموزش اما قصد داریم یکی از الگوریتم مهم و ضروری در این حوزه با نام SVM را به شما معرفی کنیم. با معرفی معروفترین الگوریتمهای یادگیری ماشین، همراه فیسیت باشید.
الگوریتم یادگیری ماشین SVM و کاربردهای آن
این الگوریتم در اصل یکی از مدلهای یادگیری نظارت شده است، به این معنا که به مجموعهای از دادههای از قبل برچسب گذاری نیاز داریم. SVM یکی از روشهای تقریباً جدید است که در سالهای اخیر روی کار آمده و نسبت به روشها قدیمیتر، عملکرد بهتری از خود نشان داده است. این الگوریتم یادگیری ماشین جزء الگوریتمهای تشخیص الگو دستهبندی میشود که در هر دو مورد کلاسیفیکیشن و رگرسیون کاربرد دارد اما بیشتر دز مسائل کلاسیفیکیشن از آن استفاده میشوند. این الگوریتم در مواردی مانند سیستم آنالیز ریسک، سیستم راهنمایی اتوماتیک اتومبیل، آنالیز بازار، پیشنهاد پروژه، مدیریت و برنامهریزی، سیستمهای مسیریابی، کلاسه بندی نمودارهای مشتری/بازار و... کاربرد دارد.
توضیح الگوریتم SVM با یک مثال
بگذارید همه چیز را با یک مثال پیش ببریم. فرض کنید فیسیت یک وب سایت با خدمات مختلف است که سرویسهای مختلفی را ارائه میدهد و دائماً ایمیلهای متفاوتی را دربارهی پیگیری سرویسها، اطلاع از طرحهای جدید و... ردیافت میکند. فرض کنید در یک برحهی زمانی برای ما مهم است که تبلیغات بیشتری را دریافت کنید و از این رو نیاز داریم تا با سرعت بالا، ایمیلی که برای سفارش سرویس و یا تبلیغات ارسال شدهاند را شناسایی کنیم. شاید اولین راه حلی که به ذهنمان بیاید، پیدا کردن برخی کلماتی است که ممکن است در ایمیلهایی با این مزمون استفاده میشوند. پیدا کردن این کلمات مشکل و زمانبر است و ممکن است نتوانیم تمامی کلماتی که نیاز است را پیدا کنیم.
در مقابل روش بهتری وجود دارد و آن یادگیری ماشین است. اگر از الگوریتم SVM استفاده کنیم، در مرحلهی اول به تعدادی ایمیل نیاز داریم که هر چه تعدادشان بیشتر باشد، بهتر است. برچسب گذاری کردن این ایمیلهای اولیه، اولین گامی است که باید برداریم. کافی است آنها را بررسی کرده و در یکی از دستههای تبلیغاتی و غیرتبلیغاتی قرار دهیم.
در مثال ما که دادهها ساده هستند و در دو دسته قرار میگیرند، SVM یک مدل خطی را یاد میگیرد. درواقع SVM یک خط را ایجاد میکند که ایمیلها را به دو دسته تقسیم میکند. یافتن همین خط، خودش مسئلهی مهمی در این روش است.
الگوریتم یادگیری ماشین SVM در واقعیت
برای استفاده از این الگوریتم، در ابتدا باید دادهها در یک فضای n بعدی مدل کنیم که n تعداد ویژگیهایی است که از دادهها داریم. حالا باید خط (یا به عبارت دیگر یک ابرصفحه) را پیدا کنیم که به بهترین شکل، دادهها را از هم جدا کند.
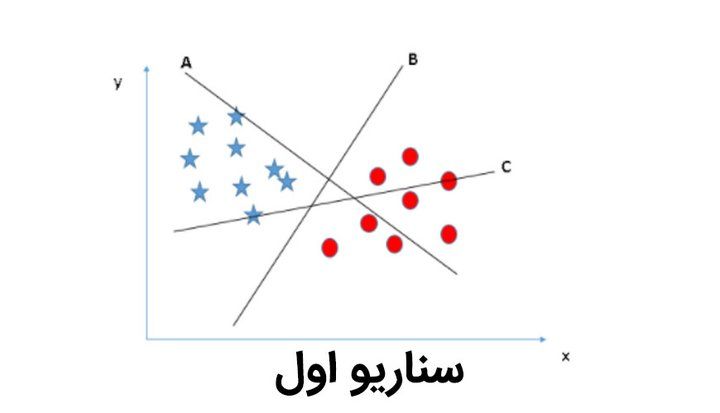
بیایید چند تصویر زیر را بررسی کنیم و نحوهی انتخاب خط مناسب را تحلیل کنیم. در شکل اول، دو خط A و C دادهها را به درستی تقسیم بندی نمیکنند و این خط B است که تقسیم بندی درستی دارد.
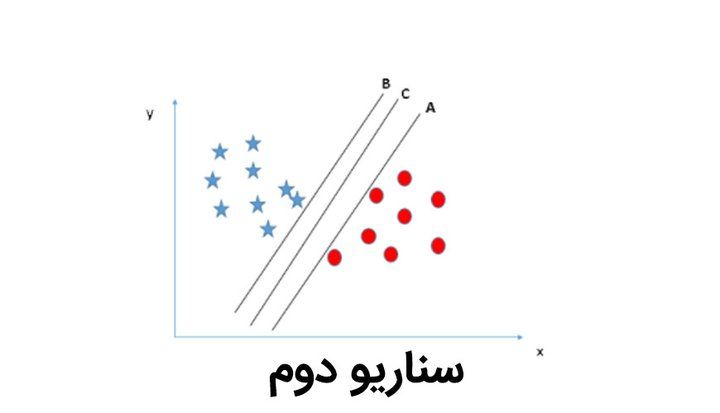
در تصویر دوم اما سه خط A و B و C، تقسیم بندی درستی انجام میدهند. از بین این خطوط کدامیک انتخاب بهتری است؟ بدون شک خط C بهترین انتخاب است زیرا فاصلهی این خط تا نقاط حاشیهای هر دسته بندی، حداکثری است. درواقع در صورتی که خطی را انتخاب کنیم که این فاصلهی حداکثری را نداشته باشد، ممکن است در طبقه بندی دادهها، دچار اشتباه شود.
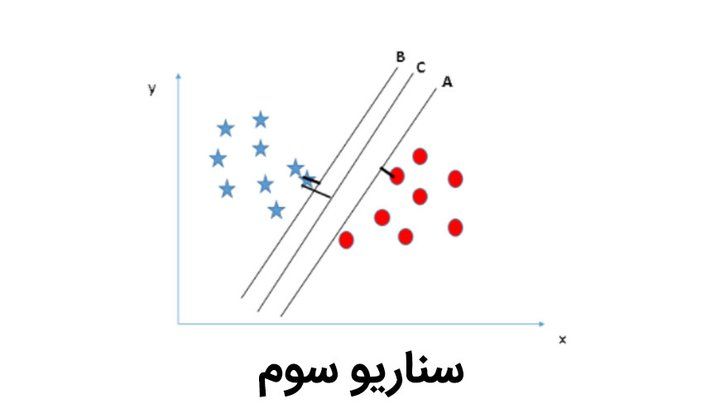
نکتهی دیگری که در SVM وجود دارد، در نظر نگرفتن دادههایی است که اصطلاحاً به آنها دادههای دور افتاده میگوییم.
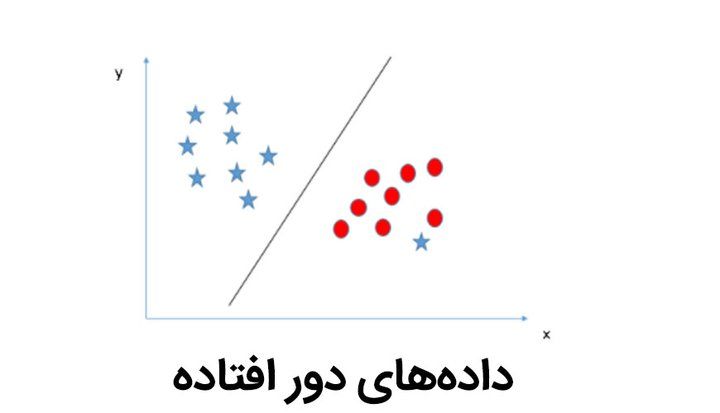
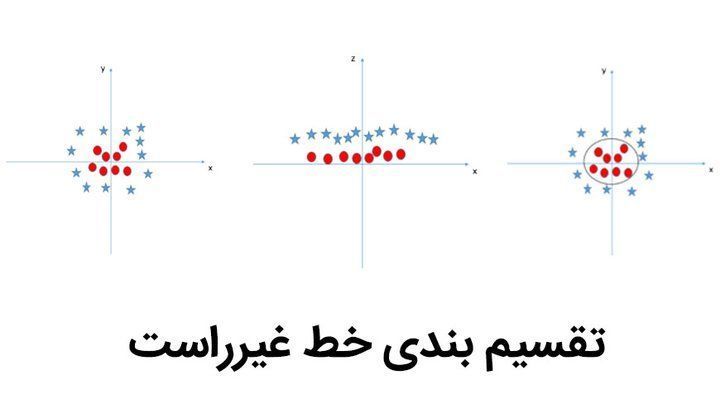
گاهی اوقات اما دادهها به گونهای توزیع شدهاند که با خط راست نمیتوان آن را تقسیم بندی کرد. از اینرو در این شرایط میتوانیم دادهها را روی نموداری با محورهای X و Z نمایش دهیم به نحوی که Z، مجموع توان دوم X و Y باشد.
اخبار مرتبط:
یادگیری ماشین چیست و چه کاربردی دارد؟
اگر به اخبار دنیای تکنولوژی علاقه مند هستید، ما را در شبکههای اجتماعی مختلف تلگرام، روبیکا، توییتر، اینستاگرام و آپارات همراهی کنید.
منبع خبر: faceit

ثبت نظر